
本地部署 DeepSeek-R1 简明指南
1. 先准备好你的电脑环境
– 系统建议:优先选Ubuntu(其他Linux发行版也行,但Mac和Windows可能有坑)
– Python:3.8或更高(保险起见用3.10)
– 硬件:有NVIDIA显卡的话体验更好(显存至少8G起步,不然大模型跑不动)
bash
新手注意:下面这行是安装基础工具,如果系统没装过git和pip就执行
sudo apt update && sudo apt install -y git python3-pip
建议搞个虚拟环境,避免包冲突(用conda或venv都行)
python3 -m venv myenv 创建
source myenv/bin/activate 激活(退出时用deactivate)
第1步:安装ollama
官方下载地址:https://ollama.com,下载安装。
安装完在cmd里运行 ollama -v ,能正确显示版本号就表示安装成功了


第2步:运行模型(仅需1条命令)
进入 ollama 的 deepseek-r1 介绍页面,根据自己的硬件情况,选择一个合适的版本,复制命令到cmd运行即可(建议32b及以上)
https://ollama.com/library/deepseek-r1:32b
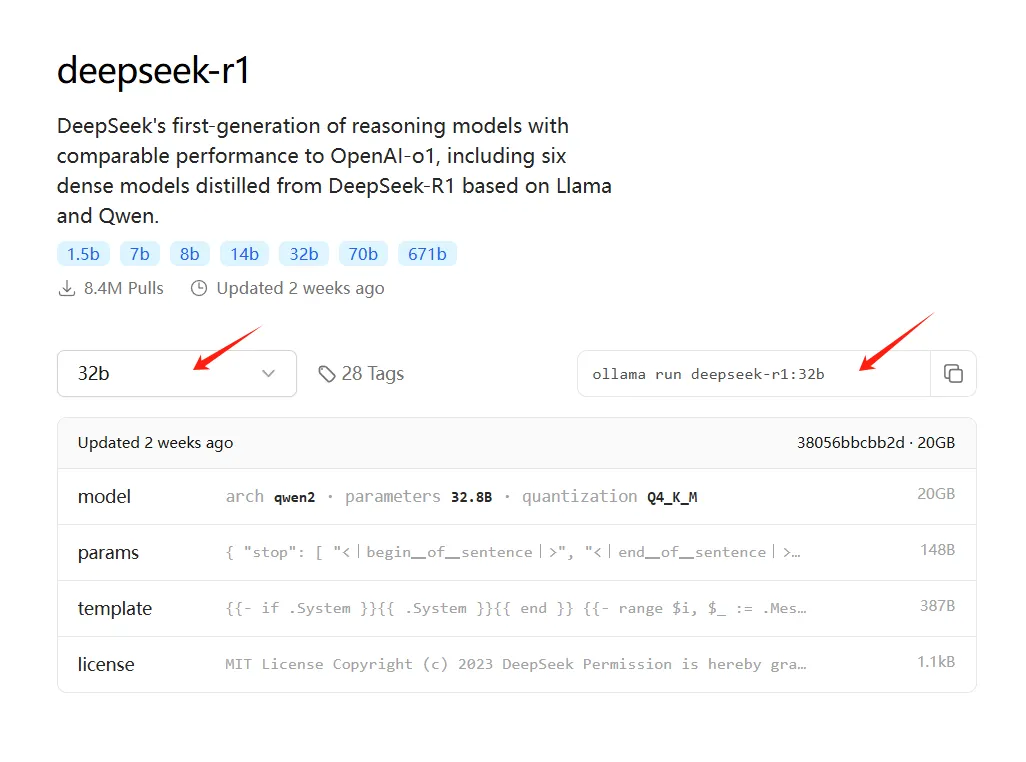
例如7b模型: ollama run deepseek-r1:7b
首次运行会自动下载模型(最后1%下载很慢,可 ctrl+c 中断后重新运行命令,续传就快了)
运行完命令可在控制台直接对话,如下图(Windows),linux同样的命令:

第3步:将API地址配置到后台
Ollama默认服务端口是11434,其提供的OpenAI格式的API地址为:
http://[ip地址]:11434/v1/chat/completions
将此地址填到后台就可以在线调用了:
最后,附几个ollama常用命令:
ollama -v :查看ollama版本号
ollama run [模型名称] :运行一个模型
ollama serve :启动ollama服务
ollama list :列出本地所有可用的模型
ollama rm [模型名称] :删除一个已安装的模型
2. 下载模型文件(关键步骤!)
– 重点提醒:模型文件通常很大(几十GB),确保硬盘空间足够!
– 官方源:如果有GitHub仓库,直接clone(但可能不带权重文件)
– Hugging Face:更可能找到完整模型,用git lfs下载:
bash
git lfs install 首次使用需要安装lfs
git clone https://huggingface.co/作者名/模型名
如果断线了可以加这句恢复下载:git lfs pull
3. 安装依赖(容易踩坑的地方)
– PyTorch:一定要选对CUDA版本!用`nvidia-smi`看右上角CUDA Version,比如11.8就装`cu118`
bash
示例:CUDA 11.8的安装命令
pip3 install torch torchvision torchaudio index-url https://download.pytorch.org/whl/cu118
其他依赖(假设项目有requirements.txt)
pip install -r requirements.txt
如果报错,试试逐个安装,可能版本冲突
4. 跑个简单测试(验证是否成功)
python
from transformers import AutoTokenizer, AutoModel
model_path = “./你下载的模型文件夹路径”
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path).to(“cuda”😉 有GPU的话
随便问个问题试试
input_text = “北京有什么好玩的地方?”
inputs = tokenizer(input_text, return_tensors=”pt”😉.to(model.device)
output = model.generate(**inputs, max_new_tokens=100)
print(“模型回答:”, tokenizer.decode(output))
真人经验提醒:
1. 显存不足:
– 尝试`model.half()`用半精度
– 加`load_in_8bit=True`参数(需要`bitsandbytes`库)
– 终极方案:换卡/租云服务器(A10/A100)
2. 下载卡住:
– Hugging Face经常断连,用`HTTPS_PROXY=http://你的代理IP:端口`加代理
3. 报错找不到模块:
– 检查虚拟环境是否激活
– 用`pip list`看是否漏装包
4. 回答乱码:
– 调低`temperature`参数
– 检查tokenizer是否加载正确
最后啰嗦一句:
– 模型文件路径别带中文!
– 首次加载会较慢(可能要5-10分钟)
– 记得看官方文档的额外说明(比如是否需要申请权重许可)
本站内容由用户自发贡献,该文观点仅代表作者观点。本站仅提供存储服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请联系我删除。
