
运行大型机器学习模型时,选择合适的GPU对于确保训练过程的效率和性能至关重要。以下是推荐的GPU选项:
1. NVIDIA RTX 4090:这是一款消费级顶级GPU,拥有24GB显存,适合个人研发项目和中等规模的模型训练。
2. NVIDIA A100:提供80GB显存,适合大规模数据和复杂模型的公司级应用。
3. NVIDIA A800:作为A100的后继产品,提供了相似的显存容量,适用于大模型训练。
4. NVIDIA H100/H800:这些是基于Hopper架构的最新GPU,提供了更高的性能和显存带宽,非常适合大模型训练。
5. NVIDIA T4:对于模型微调和推理任务,T4是一个更经济的选择,适合日常使用。
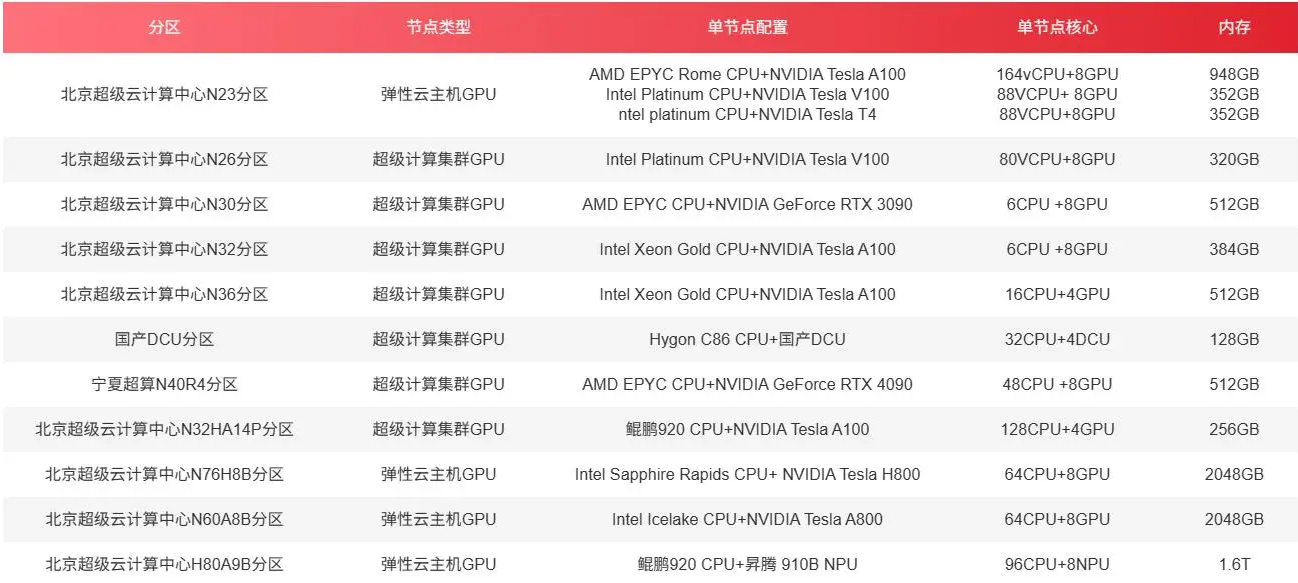
 在选择GPU时,除了考虑显存容量外,还需要考虑以下因素:
在选择GPU时,除了考虑显存容量外,还需要考虑以下因素:
计算能力:GPU的CUDA核心和Tensor核心数量影响其并行处理能力。
显存带宽:GPU与显存之间的数据传输速度,影响训练速度。
多GPU支持:某些模型可能需要多GPU并行处理,需要确保GPU支持必要的通信接口,如NVLink。
对于本地个人研发项目,消费级GPU如GeForce RTX 4090可能已足够。而对于企业的大规模数据处理,推荐使用NVIDIA A100或A800这样的高性能GPU。
如果追求性价比,可以考虑使用第三方服务,如AutoDL提供的4090服务。对于云服务,阿里云、腾讯云和火山引擎等提供了不同配置的GPU实例,可以按需选择。
如果考虑使用Google Cloud,TPU是专门用于加速机器学习的硬件,适合大规模深度学习任务。在选择之前,建议详细分析模型的需求,考虑数据规模、训练速度和预算,以确定最适合项目的GPU类型。
本站内容由用户自发贡献,该文观点仅代表作者观点。本站仅提供存储服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请联系我删除。
